Regular expressions are a handy ‘mini-language’ for parsing text data. Instead of writing complex Python code to parse text you can write a regular expression that uses a special syntax designed for easily parsing and capturing information inside text. In a few characters or lines of regular expression you can perform very complex parsing that might takes tens or hundreds of lines of Python code!
One great use for regular expressions is parsing the response from GPS units that send data in NMEA formatted text strings. Using a regular expression you can break apart the GPS response into components like latitude, longitude, and more with ease. Let’s look at a quick example of how to parse a NMEA GGA sentence like the following:
$GPGGA,123519,4807.038,N,01131.000,E,1,08,0.9,545.4,M,46.9,M,,*47
If you look at the format for NMEA GGA sentence data you can see the following information is encoded in the sentence:
Where:
GGA Global Positioning System Fix Data
123519 Fix taken at 12:35:19 UTC
4807.038,N Latitude 48 deg 07.038' N
01131.000,E Longitude 11 deg 31.000' E
1 Fix quality: 0 = invalid
1 = GPS fix (SPS)
2 = DGPS fix
3 = PPS fix
4 = Real Time Kinematic
5 = Float RTK
6 = estimated (dead reckoning) (2.3 feature)
7 = Manual input mode
8 = Simulation mode
08 Number of satellites being tracked
0.9 Horizontal dilution of position
545.4,M Altitude, Meters, above mean sea level
46.9,M Height of geoid (mean sea level) above WGS84 ellipsoid
(empty field) time in seconds since last DGPS update
(empty field) DGPS station ID number
*47 the checksum data, always begins with *
To parse this data with a regular expression you’ll first need to import the ure module in MicroPython:
import ure
Note that not every board has the flash memory available to support the ure module. The ESP8266 and pyboard do currently support its use, but the SAMD21 & CircuitPython don’t yet enable it.
Once the ure module is imported using it is nearly identical to the re module in desktop Python. In particular you can use the match function to try to match a regular expression to a string of text.
Before you can use match you need to create a regular expression the describes the data you’re trying to parse. Check out the Python re module documentation for more details on crafting a regular expression (there are even entire books on the subject!). Here’s an example regular expression to parse the first few parts of the sentence and get the time, latitude, longitude, and fix quality:
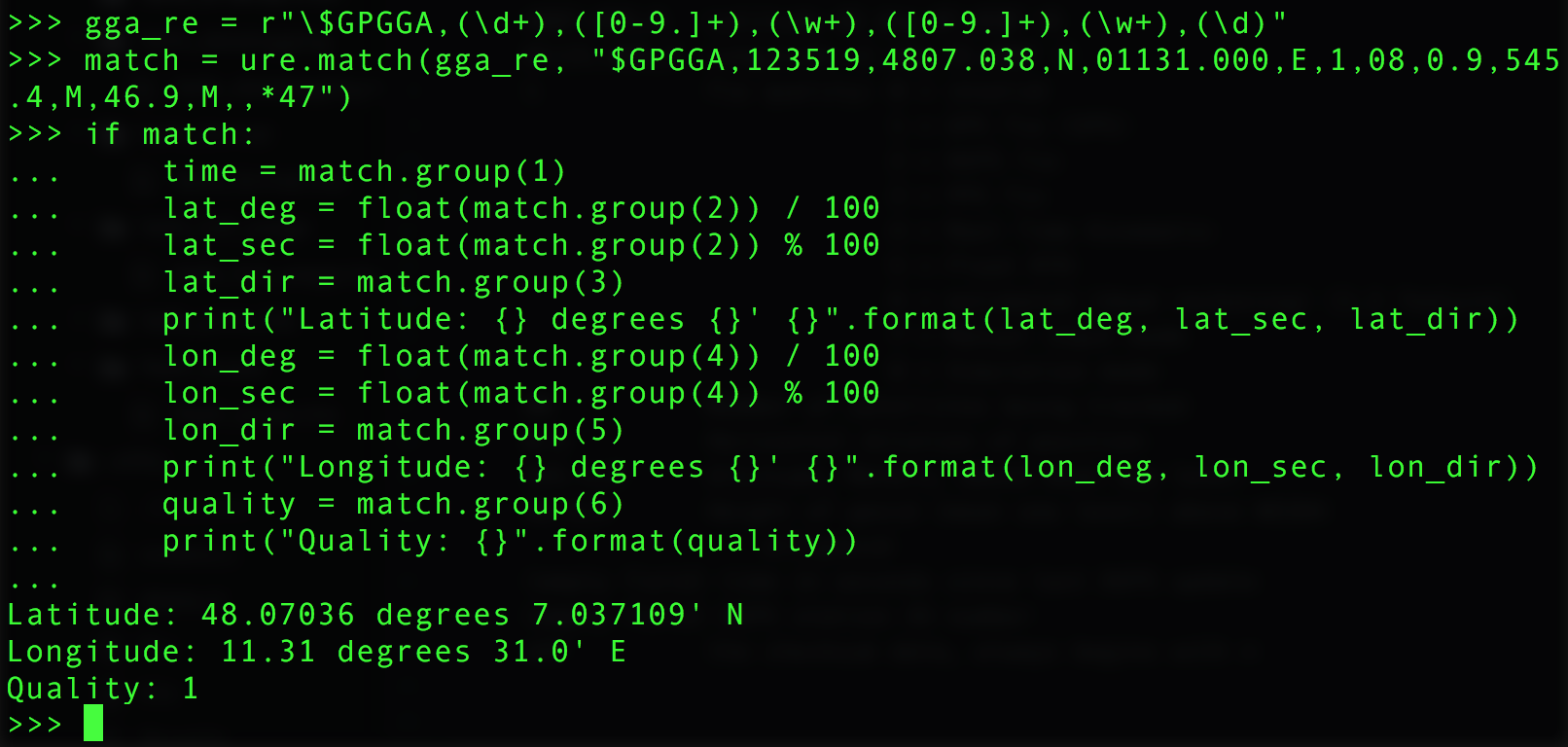
gga_re = r"\$GPGGA,(\d+),([0-9.]+),(\w+),([0-9.]+),(\w+),(\d)"
This looks a little scary but break it down part by part and you can see how it identifies each component between commas. The ‘$GPGGA’ string is expected to come first (note the $ character has to be escaped with a slash in front since it has a special meaning in regular expressions, and if you’re really paying attention you’ll also see the r in front of the string which tells python this is a ‘raw’ string so the escape slash \ itself doesn’t need to be escaped–phew!). Then some number of digits for the time, some number of digits or decimal point for latitude, some characters for latitude direction (like N, W, NNW, etc.), the same for longitude, and finally a single digit for the fix quality. Notice some components are surrounded in parenthesis, this means the regular expression will capture the value inside and make it available to easily read from Python later.
Let’s use the expression to match our NMEA GGA string! Try running:
match = ure.match(gga_re, "$GPGGA,123519,4807.038,N,01131.000,E,1,08,0.9,545.4,M,46.9,M,,*47")
If the returned match object evaluates to True then our string matched the regular expression and we can extract the data. You can call the group function and pass it the index to the captured value you’d like to retrieve. Note this index is 1-based which means the first parenthesis item in the regular expression is group 1, the second is group 2, and so forth. Here’s how to test and parse the matched groups:
if match:
time = match.group(1)
lat_deg = float(match.group(2)) / 100
lat_sec = float(match.group(2)) % 100
lat_dir = match.group(3)
print("Latitude: {} degrees {}' {}".format(lat_deg, lat_sec, lat_dir))
lon_deg = float(match.group(4)) / 100
lon_sec = float(match.group(4)) % 100
lon_dir = match.group(5)
print("Longitude: {} degrees {}' {}".format(lon_deg, lon_sec, lon_dir))
quality = match.group(6)
print("Quality: {}".format(quality))
Notice the group function is used to pull out parts of the text that were matched to the regular expression components in parenthesis. This makes it really easy to extract latitude, longitude, and more from the string! Instead of writing complex Python code to split the string apart and find each comma separated value you’re instead describing the data you expect with the regular expression and letting the ure module handle the rest.
Whenever you have complex text parsing needs in Python and MicroPython consider regular expressions as a powerfu tool in your toolbox. Be careful though sometimes regular expressions can get quite complex and more advanced manual parsing code is better suited to the task. JWZ said it best, “Some people, when confronted with a problem, think ‘I know, I’ll use regular expressions.’ Now they have two problems.” 🙂
